No mundo moderno, onde o conteúdo desempenha um papel importante no campo da informação, sua geração ocorre a passos largos. Muitos utilizam algoritmos de IA para reduzir o tempo de criação de textos e facilitar sua tarefa. Sim, a ideia parece boa - por que não aproveitar os benefícios da civilização?
Mas, por outro lado, os trabalhos se tornam menos únicos, perdem o estilo autoral e a qualidade. Por isso, junto com os geradores de texto, são frequentemente usados serviços especiais de página pra verificar conteúdo de IA, que detectam vestígios de IA após uma análise detalhada do conteúdo. Ferramentas de detecção como o Smodin funcionam em diferentes idiomas, incluindo o português. Como a análise multilíngue afeta os resultados e quais são as particularidades da verificação em diferentes idiomas - essa questão será analisada a seguir.
Como o fator linguístico afeta a detecção
Um dos principais algoritmos do detector de IA permite reconhecer padrões de máquina por meio de um sistema de probabilidade. Em outras palavras, o programa prevê quais palavras ou frases seguirão em seguida, com base no significado. Afinal, a IA funciona de acordo com um esquema específico. Consequentemente, essa característica será diferente entre diferentes modelos de linguagem.
A maioria das IAs usa o inglês para criar conteúdo. Esse mesmo idioma é considerado universal para sites como o Smodin. Por isso, os textos produzidos nesse idioma tornam-se mais previsíveis.
Se o autor deixar o texto gerado sem editar, ele terá muitos clichês e frases padrão. O detector os identifica rapidamente em qualquer idioma. Mas quando se trata de expressões de gíria ou nuances morfológicas em idiomas diferentes do inglês, o serviço pode errar nos resultados.
Características do idioma português para detectores
É mais difícil para o detector reconhecer os padrões da IA quando o conteúdo é criado em português. Isso se explica por vários fatores:
- o português tem dialetos brasileiros e europeus, que o detector de IA deve ser capaz de distinguir; - é mais difícil para o programa processar conteúdo que usa muitas formas diferentes de verbos; - a possibilidade de construir frases com uma ordem incomum de palavras torna o texto imprevisível. Como qualquer outro idioma, o português é repleto de características únicas. Por isso, nem sempre os programas de detecção de IA conseguem identificar imediatamente as armadilhas. No entanto, eles aprendem novas técnicas e, gradualmente, apresentam bons resultados na análise multilíngue.
Comparação de resultados em diferentes idiomas
Devido ao aumento da demanda por verificação de conteúdo, cada vez mais serviços estão migrando para o formato multilíngue. No entanto, nem todos os detectores são capazes de trabalhar adequadamente com diferentes idiomas, incluindo o português. Alguns serviços traduzem os textos para o inglês e realizam a verificação, mas o resultado da análise será incorreto. É importante escolher um programa que saiba verificar textos no idioma original. Naturalmente, levando em consideração todas as suas características culturais e morfológicas.
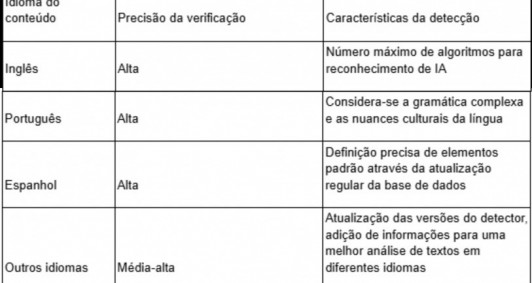
A tabela apresenta as nuances da análise de trabalhos em diferentes idiomas. Como exemplo, foi escolhido o detector AI Smodin.
Problemas dos textos multilíngues
Trabalhar com conteúdo em diferentes idiomas apresenta muitas tarefas complexas para os detectores. Se tomarmos como exemplo o português ou qualquer outro idioma além do básico, frequentemente encontramos resultados falsos positivos na verificação. Especialmente em situações em que vários idiomas estão misturados em um mesmo trabalho. O programa começa a “duvidar” da autoria humana do conteúdo multilíngue. Ou, ao contrário, considera um texto escrito por uma pessoa como sendo produzido por uma máquina. Podem surgir problemas quando o conteúdo é traduzido pelo Google do inglês ou de outro idioma para o português. Mesmo que o texto tenha sido editado manualmente, após a tradução, o detector pode concluir que o trabalho foi feito por IA.
Perspectivas de desenvolvimento da detecção multilíngue
Nos próximos anos, espera-se que a área de análise multilíngue para padrões de IA se desenvolva rapidamente. Em poucos anos, os serviços de detecção poderão aprender a trabalhar de forma eficaz com conteúdo em diferentes idiomas, incluindo o português. Quais são as previsões consideradas mais prováveis nessa área:
1- Aumento do volume de informações em português e outras línguas para o treinamento de grandes serviços de verificação. 2- Implementação de modelos de análise para a detecção de cada língua individualmente. 3- Análise detalhada de incompatibilidades de estilo, construção única de frases e expressões, verificação mais profunda do código cultural. 4- Redução da parcialidade na verificação para conteúdo não criado por um falante nativo. 5- Utilização de pipelines sensíveis ao idioma, que se adaptam às nuances morfológicas individuais do idioma.
Planeja-se que, já em 2027-28, os detectores aprenderão a realizar análises praticamente idênticas em diferentes idiomas. Para o programa, não haverá quase nenhuma diferença em procurar padrões de IA em conteúdo em inglês, português ou espanhol. Os detectores crescerão significativamente em termos de eficácia e confiabilidade dos resultados, independentemente do idioma.
Por que o inglês é determinado com mais precisão do que outros idiomas
Muitos criadores de conteúdo certamente notaram que os textos em inglês são melhor processados pelos detectores de IA. Na verdade, esse idioma é considerado o padrão para uma análise eficaz. Essa característica está relacionada a vários motivos. A lista destaca os principais motivos dessa tendência entre os serviços populares:
- a maior parte das informações no Large Language Model está em inglês, por isso o detector aprende e detecta mais rapidamente os sinais de IA nos textos; - a inteligência artificial em inglês gera conteúdo com padrões evidentes. Ela escolhe as mesmas palavras, comprimento e estrutura das frases, modelos de discurso padrão; - os algoritmos padrão para IA e detectores são criados em inglês, como um dos idiomas mais universais do mundo; - se compararmos o inglês com os idiomas português ou espanhol, por exemplo, ele tem muito menos dialetos. Além disso, as regras ortográficas para ele não são tão rígidas quanto para a maioria dos outros idiomas.
Cada vez mais, os usuários modernos podem encontrar e aplicar detectores multilíngues. Eles não apenas suportam o reconhecimento de diferentes idiomas. Muitos deles, incluindo o Smodin, fornecem resultados de verificação estáveis, sem inúmeros erros.